Stream-based Data Compression
based on Hardware
Stream-based Data Compression
based on Hardware
データストリーム伝送路におけるロスレス圧縮技術の開発
データストリーム伝送路におけるロスレス圧縮技術の開発
【研究概要 】
通信・映像・センサといった情報源が発するデータ量の爆発的な増加に伴い、データ伝送路に超高周波での実装が要求され、困難を極める状況にある。一定のデータ塊を単位として圧縮・復号するブロッキング圧縮によるデータ量の削減は従来から行われているが、常に流れ出る高速データ源では処理が間に合わず破綻する。伝送路で直に圧縮できればよいがハードウェアで効果的に実装できる技術がない。そこで、本研究は伝送路に流れるデータの出現統計をリアルタイムに生成し、圧縮・復号するストリーム圧縮ハードウェア技術を開発する。この技術は伝送路の物理的容量限界を超えたデータ伝送が可能な高信頼コンピューティングへの基盤技術の確立を狙う。
1.研究背景
産業界では、データ伝送路に流れるデータ量の爆発的増加に対応する圧縮技術が必要とされている。PCI Express、HDMI、USBといったデータ伝送路標準はGHzに達する勢いで、それを実装するプリント基板製造の現場では複数パターンを設計し、その中から期待通りに動作するものを採用するといった非科学的開発手法を採用するまでにデータ伝送路の実装は困難を極めている。実装技術を複雑化せず転送量を増加させるには、伝送路に流れるデータを圧縮し、周波数や伝送量を減少させ、実装を簡単化するハードウェアでの圧縮技術の開発が喫緊の課題である。
その一方で、既存の圧縮技術をブロッキング圧縮からストリーム圧縮へ技術シフトを急ぐ必要がある。つまり、これまで、メモリにデータを溜めて圧縮・複合を実行するブロッキング圧縮は行われてきたが、データ伝送路の帯域が増加すると破綻する。さらに、ハードウェアで高速化しても、伝送路の性能向上に比例した回路の高速化を余儀なくされ、性能の“いたちごっこ”に陥り、技術破綻を予想できる。従って、伝送路の性能に比例したデータの高濃度化を実現できるストリーム圧縮に技術をシフトする必要があるが、ハードウェアにスケーラブルな実装が可能な技術が未踏である。データ圧縮は最頻出で最長のデータ列(シンボル列と呼ぶ)をデータの中から探し、それを単一のデータ(シンボル)に置き換えて情報量を削減するが、従来法を使うと1)シンボル列抽出処理時間予測が不可、2)シンボル変換テーブルサイズが予測不可、3)テーブルを復号側へ送信するオーバヘッド、4)テーブル自体が圧縮率を低下、という問題によって、圧縮・復号処理を伴ったデータ伝送を連続的に実行できない。
2.研究の目的
以上の背景から、本研究では、データ伝送路に流れるデータをリアルタイムに圧縮するストリーム圧縮技術の開発を目的として。本研究で扱うデータは区切りがない連続したデータである。従って、シンボル変換テーブルを送るタイミングがない。そこで、リアルタイムに圧縮側と復号側で同じテーブルを保持し、圧縮・復号を行う必要がある。これをハードウェアのデータ伝送路に組み込むために本研究は、少ないリソースで、かつ、高速に動作できる、ハードウェア化が可能な、1)ストリームデータ伝送路でのリアルタイム圧縮・復号機構をもった通信プロトコルと、2)リアルタイムにデータ出現頻度をランキングするシンボル変換テーブル更新機構の開発を目指した。これらの処理をハードウェアでスケーラブルに実施するためには、固定長のシンボル列をテーブルに登録し、さらに、テーブル容量が飽和した場合に最も使われていないシンボル列の規則を入れ替える方式を開発できれば良いことはわかっていた。このような動的管理方式によって、伝送路に流れる時々刻々と出現率が変化するデータであっても、伝送路中のデータ量の高濃度化を実現でき、伝送路のピーク性能を超えるストリーム圧縮ハードウェアが実装できる。
データストリームの統計的傾向が変化しても高い圧縮率を維持するシステムを開発するために、1)シンボルテーブル更新を可能にする通信プロトコルの開発、2)データストリームの統計的傾向を求めるアルゴリズムの開発、3)アプリケーションの開発、の3つの大テーマに分けて実施した。1)に関しては、初年度に実施し、アルゴリズムの開発とその実装方法に関して議論を重ね、ソフトウェアとハードウェアでの施策を行なった。
3.研究成果
上記の研究の背景で説明した従来からのデータ圧縮における問題点を克服する、無限に続くデータストリームに適用でき、さらに、ハードウェアで高速動作させることが可能な新しい方式LCA -DLTを提案し、ハードウェア、ソフトウェアの両面で良好な性能を示すことが出来た。この圧縮方式では、図1のように、①2つの単位データを1つに圧縮するモジュールを用意し、②そのモジュールが動的に変換テーブルを作り、③圧縮されたデータの構造に②のテーブルの作成手順を隠し持つことで、④解凍側で同一の変換テーブルを復元し、データを元に戻す。この技術では、変換テーブルを解凍側に送る必要がなく、圧縮されたデータストリームを受信し始めると、次々と解凍を行う事ができる。つまり、最初のデータが圧縮されると、そのデータは次々と解凍側に渡されて、解凍側はそれらを順次、データ構造から連想される変換テーブルを復元し、解凍していく。従って、ストリームでの圧縮・解凍処理が可能である。
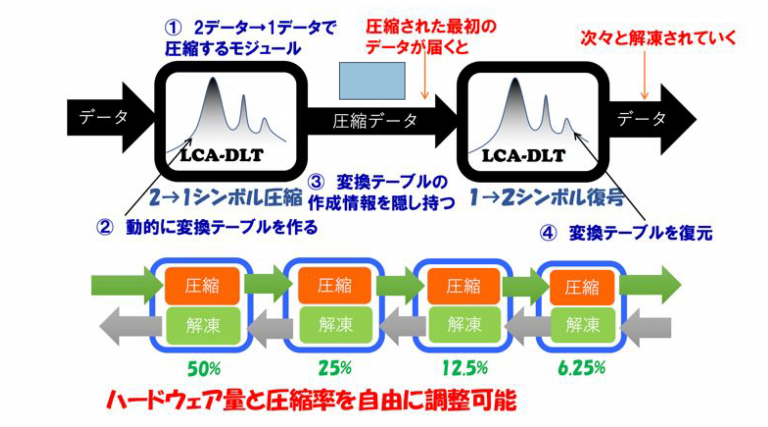
図1:ストリームデータ圧縮技術 LCA-DLT
さらに、圧縮モジュールは2データ→1データの圧縮であるため、50%しか圧縮出来ない。そのモジュールをカスケード接続することで、4段の場合、最大で1/16=25%まで理論的には圧縮できるユニバーサル性を持つ革新的な圧縮方式を開発することが出来た。本研究の学術的な意義として、これまで、メモリに保持したデータをプロセッサがランダムアクセスすることによるデータ圧縮方式のみが主流であったが、データストリームのようなランダムアクセスが不可能である特徴を持つデータ生成環境(例えば、センサのデータなど)においても適用できる新しいアルゴリズムが実現できることが証明でき、今後、ストリームデータ圧縮という新しい学術分野を期待できる。
4.さらなる改良:ASE Coding
LCA-DLTから得たリアルタイムデータ圧縮のノウハウをもとに、ASE Codingとよ新たなデータ圧縮技法を開発し、研究を続けている。ASE Codingはデータストリームのエントロピーを連続的にさらに、リアルタイムに圧縮出来る新方式である。ASE Codingも、LCA-DLTと同様に、コンパクトで定量的なハードウェアで実装することが可能である。ASE CodingはLCA-DLTに比べ、約5分の1のハードウェアリソースで実装することができることを確認している。現在、このハードウェアをつかったAIやIoT向けのアプリケーションプロセッサを開発している。
5.主な発表論文等
[雑誌論文]
- Shinichi Yamagiwa, Yuma Ichinomiya, Stream-Based Visually Lossless Data Compression Applying Variable Bit-Length ADPCM Encoding, Sensors 21(13) 4602, July 2021.
- Shinichi Yamagiwa, Koichi Marumo, Suzukaze Kuwabara, Exception Handling Method Based on Event from Look-Up Table Applying Stream-Based Lossless Data Compression, Electronics10(3) 240, January 2021.
- Shinichi Yamagiwa, Suzukaze Kuwabara, Autonomous Parameter Adjustment Method for Lossless Data Compression on Adaptive Stream-Based Entropy Coding, IEEE Access 8 186890 – 186903, October 2020.
- Shinichi Yamagiwa, Eisaku Hayakawa, Koichi Marumo, Stream-Based Lossless Data Compression Applying Adaptive Entropy Coding for Hardware-Based Implementation, Algorithms 13(7) 159, June 2020.
- Koichi Marumo, Shinichi Yamagiwa, Ryuta Morita and Hiroshi Sakamoto, Lazy Management for Frequency Table on Hardware-Based Stream Lossless Data Compression, Information7(4)63, MDPI, October 2016.
[学会発表]
- Shinichi Yamagiwa, Eisaku Hayakawa, Koichi Marumo, Adaptive entropy coding method for stream-based lossless data compression, In Proceedings of the 17th ACM International Conference on Computing Frontiers 265-268, May 2020.
- Shinichi Yamagiwa, Ryuta Morita and Koichi Marumo, Reducing Symbol Search Overhead on Stream-based Lossless Data Compression, In Proceedings of ICCS 2019, LNCS, Springer11540 619-626, June 2019.
- Shinichi Yamagiwa, Ryuta Morita and Koichi Marumo, Bank Select Method for Reducing Symbol Search Operations on Stream-based Lossless Data Compression, Data Compression Conference 2019, March 2019.
- Koichi Maruo, Shinichi Yamagiwa, Time-sharing Multithreading on Stream-based Lossless Data Compression, In Proceedings of The Fifth International Symposium on Computing and Networking 305-310, IEEE, November 2017.
- Shinichi Yamagiwa, Koichi Maruo and Hiroshi Sakamoto, Stream-based Lossless Data Compression Hardware using Adaptive Frequency Table Management, In Proceedings of VLDB2015/BPOE-6, Springer 133-146, September 2015.
- Shinichi Yamagiwa, Hiroshi Sakamoto, A reconfigurable stream compression hardware based on static symbol-lookup table, 2013 IEEE International Conference on Big Data 2013 86-93, October 2013.
[その他]
- (プレスリリース)筑波大学 「ビッグデータ時代に対応した新しいロスレスデータ圧縮技術を開発 ~コンパクトにハードウェア実装可能な高速ストリームデータ圧縮・復号化技術~」2015年8月21日
- (受賞)大学発ベンチャー表彰「科学技術振興機構理事長賞」 受賞名:ストリームデータ圧縮技術〜Data Copression3.0〜 (2018年8月)
- (受賞)常陽ビジネスアワード 最優秀賞(成長事業部門)「Data Compression3.0〜新ロスレスデータ圧縮技術がつくるスマートライフのためのテクノロジ〜」(2016年5月)
- (受賞)Embedded Technology Award 2015「特別賞」(受賞技術:高性能ストリームデータ圧縮技術〜ストリームを高速にコンパクトに。未来のロスレス圧縮のカタチ)(一般社団法人 組込みシステム技術協会)(2015年11月)
- (受賞)Best Paper Award(VLDB2015/BPOE-6)(2015年9月)Shinichi Yamagiwa, Koichi Maruo and Hiroshi Sakamoto, Stream-based Lossless Data Compression Hardware using Adaptive Frequency Table Management, In Proceedings of VLDB2015/BPOE-6, pp.133-146, Springer, Sep 2015.)
- (報道)常陽新聞2015年8月27日「新方法のデータ圧縮開発」筑波大准教授山際伸一さんら 様々な機器に実装可能
[獲得予算]
- (受託研究)科学技術振興機構 さきがけ(IoTが拓く未来・徳田英幸総括)「高性能ストリームデータ圧縮技術の開発」(研究代表者 山際伸一)、2020年11月1日 ~ 2024年3月31日
- (科研費)基盤研究B 代表, “大局的エントロピー予測によるデータ圧縮の最適化技法の開発”, 2020-2023,(研究代表者 山際伸一)
- (科研費)挑戦的研究(萌芽) 代表, “知覚的エントロピー劣化によってストリームデータの圧縮率の制御は可能か?”, 2018-2021, (研究代表者 山際伸一)
- (科研費)基盤研究B 代表, “データストリーム伝送路におけるロスレス圧縮技術の開発”, 2015-2018, (研究代表者 山際伸一)