ストリーム指向プログラムのマクロ並列化の研究
ストリーム指向プログラムのマクロ並列化の研究
【 研究概要 】
ストリーム指向プログラムはGPUといったメニーコアアクセラレータの普及によって、科学技術計算から産業用製品にまで利用されている。その単体性能は、チップ内における密並列によるプログラム実行により高い性能を示す。しかし、複数のアクセラレータを使った超並列計算を考慮すると、タスクの分割と通信タイミングを配慮したプログラム開発が必要になり、性能をスケーラブルに維持したままの開発が困難となる。本研究では、このようなGPUでのストリーム指向プログラムを対容積・対電力での計算能力の高密度化をねらい、自動的に複数のGPUで並列化し、スケーラブルに性能向上が可能なプログラミング基盤技術を開発する。
研究背景
メモリをランダムアクセスする従来からのプログラミング手法に代わる新たなパラダイムとして、ストリーム指向プログラムが利用されている。特にGPU の数値計算への利用が普及し、OpenCL や CUDA といったプログラミング環境の拡充が後押しする形で科学技術計算から産業用製品にまで利用されている。中でも科学技術計算に関しては、ストリーム指向プログラムのデータ並列性を生かしGPU 内部の小さなプロセッサによる密並列実行により、従来のフォンノイマン型 CPU の性能に比べ、10-100 倍の性能を実現している。最近では、複数GPU をネットワークで接続したGPU クラスタ環境が注目されている。
GPU クラスタでは複数 GPU 間で、ストリーム指向プログラムのマクロな並列化が考慮される。これは、メモリアクセス範囲を分割する従来からのベクトル化とは異なり、データ ストリームを分割することで並列実行を狙う。この時、GPU 内部のミクロ並列化では必要がないGPU チップ間での通信が必要となる。プログラマは通信ライブラリを使って、GPU 間のデータストリームの移動を実装する。このプログラム開発には、GPU での「ストリー ム指向プログラムの実行」と、「GPU 間通信」が混在し、互いの実行タイミングの最適化は 困難を極める。通信の最適化を含めた並列化を行い、GPU の潜在性能の 100%近い実効性 能を引き出す新技術が開発できれば、小規模 GPU クラスタ上でさえペタ FLOPS スケールの 実効性能を実現するプログラム開発が可能 になり、対容積・対電力での計算能力の高密 度化が可能になる。
研究の目的
(1)単体のGPU 向けストリーム指向プログラムをマクロ並列化するコンパイラの開発
GPU 単体の潜在性能を極限まで引き出すことを目的とし、後述の複数のGPU を利用する際にも全体の計算性能が極限まで高められる基盤技術を開発する。
(2)複数GPU の利用を可能にする通信コードを自動的に生成するプログラム変換技術
複数のGPU で並列計算をするために、逐次的に記述されたプログラムを並列実行可能な形に変換するための基盤技術を開発する。
(3)上記2つの基盤技術を用い、自然科学等のアプリケーションに応用する
研究内容
(1)単体GPU の潜在性能を引き出す技術の開発
① GPU とCPU 間のデータ交換に伴うオーバヘッドの削減方法の開発
GPU と CPU は PCI バスといった周辺バスによって接続されており、CPU が GPU を制御することで、並列計算プログラムとデータをダウンロードして、それを実行する。このデータを再度、GPU 側に転送するオーバヘッドはGPUでのプログラム実行時間に対して大きく、オーバヘッドになる。このデータ転送を削減するための方策を開発すると共に、その機能を容易に利用できるプログラミング方式を開発する。
② GPU におけるプログラム交換オーバヘッドを削減するための実行方式の開発
上記の①のデータ交換に伴う問題とともに、 GPU で異なるプログラムを実行する際にも CPU 側からプログラムをダウンロードし直す必要があり、オーバヘッドとなっている。このオーバヘッドを削減するための方法、および、その機能を容易に使えるプログラミングインタフェースを開発する。
(2)複数GPU を並列利用するためのプログラム変換方式の開発
プログラムを部分に区切った、または、並列実行するためにスケジューリングされた場合、それらを複数のGPU でパイプライン的に処理する機構を開発する。
(3)計算物理学への応用
上記の性能改善策を利用し、計算物性物理学のシミュレーションに応用する。
研究成果
本研究では、これまでの研究成果を元にしてさらなる飛躍を目指した。この成果は図1に示す、flow-model と呼ばれる GPU 向けプログラムとその入出力を定義したデータ構造を、GPU にマップすることにより並列計算を容易に実行する Caravela と呼ばれるプログラミング環境を開発していた。 Flow-model を複数つなげ合わせることでアプリケーションのアルゴリズムを構成し、それぞれの flow-model が単体 GPU にマップされる。この研究基盤を利用し、以下の成果を得ることができた。
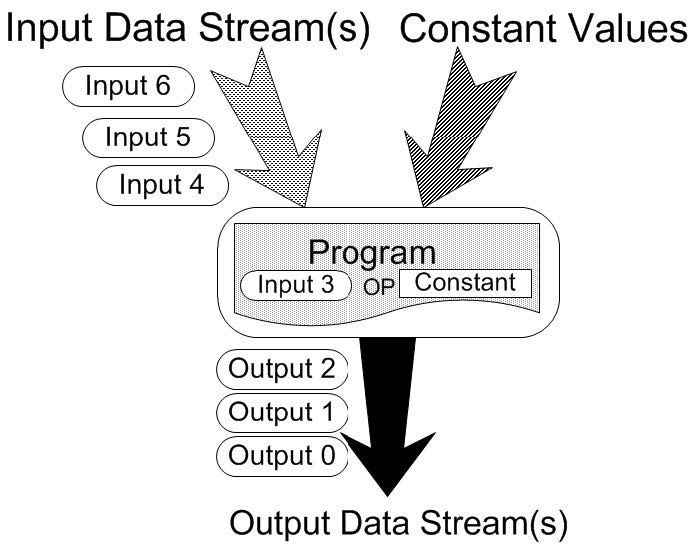
図1:Caravelaのflow-model
GPU 単体性能におけるホスト CPU との無通信でのプログラム実行方式
Swap 方式と呼ばれるGPU への入出力バッファを、GPU がプログラム実行前後でそのポインタ操作のみで入れ替えが可能な方法を使うと、出力データを再利用するような再帰的なプログラムの性能を劇的に向上することができる。このデータ移動に関する最適化のみならず、本研究では、複数の GPUのプログラムをまとめ、スワップ方式と組み合わせることによって、それをGPU 側で連続実行するとプログラムの入れ替えをすることなく、アプリケーションの実行が可能な Scenario-based Execution 方式を開発した。 ス ワ ッ プ 方 式 と Scenario-based Execution 方式を使うと、ホストCPU からのデータやプログラムの移動を一切、行わない、無通信実行が可能になる。これら方式を用い、flow-model の入出力のコネクションを、従来のシェルプログラムのようにスクリプトで記述しておけば、スワップ方式も含め、自動実行し、flow-model をGPUにマップして実行してくれる簡易なプログラム環境 CarShを開発した。 CarSh は GPU といったアクセラレータとばれるCPU と協調動作する並列プロセッサを持ったシステムに全て適用でき、さらに、GPU 等をスクリプトだけで実行できるシステムである。CarSh は図2に示すようなシステム階層の上に実装され、GPU における詳細なプログラム方法を知らないプログラマでも、GPUのプログラムを用意して、flow-model を定義し、スワップ方式を暗に利用しながら、GPUの潜在性能を引き出した並列計算が可能になった新しいプログラミングインタフェースを提供することができた。
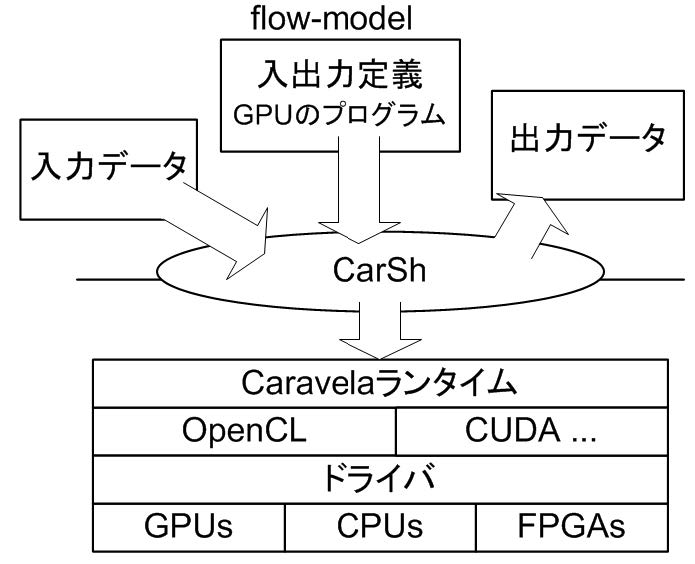
図2:CarShのシステム構成
複数GPU での並列実行パイプラインを自動生成するコンパイラ
CarSh で複数のflow-modelを接続したアプリケーションが実行できるようになったが、1つのGPU のみを逐次的に使い回す方法で実行していた。それを複数のGPU でパイプライン実行させる自動並列化方式 PEA-ST を開発した。
PEA-ST アルゴリズムは図3に示すような複数の flow-model をつないだアプリケーションから並列性を自動的に抽出し、マクロ並列化を実現する。マクロに並列化された複数の flow-modelは複数のGPU に並列に割り当てられ、同時に実行される。図3では、この並列化のステップを示している。図3(a)は単純に接続された flow-model を並列化している様子をしめす。図3(a)-(3)に示すように 3つのGPU で並列実行でき。さらに、これらの GPU の間での通信を自動生成する。図3(b)は結果がフィードバックされる flow-model間の依存関係がある場合を示している。この場合、どの flow-model が並列実行できるかを目視だけで判断することは難しいが、図3 (b)-(3)にあるとおり、3 つのGPU で実行できる自動並列化が行われる。
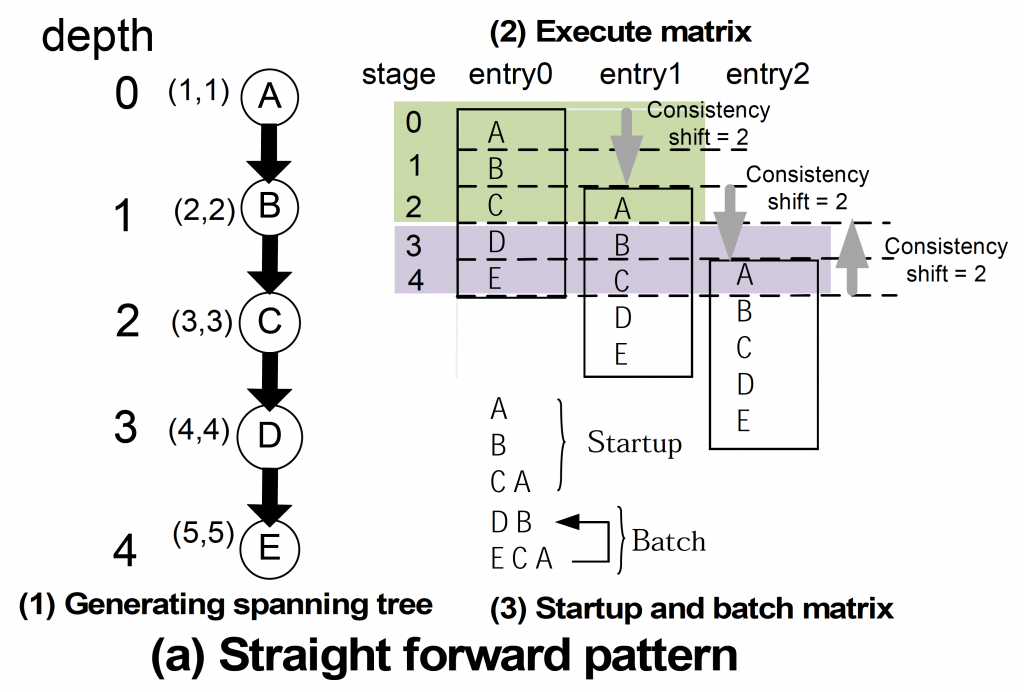
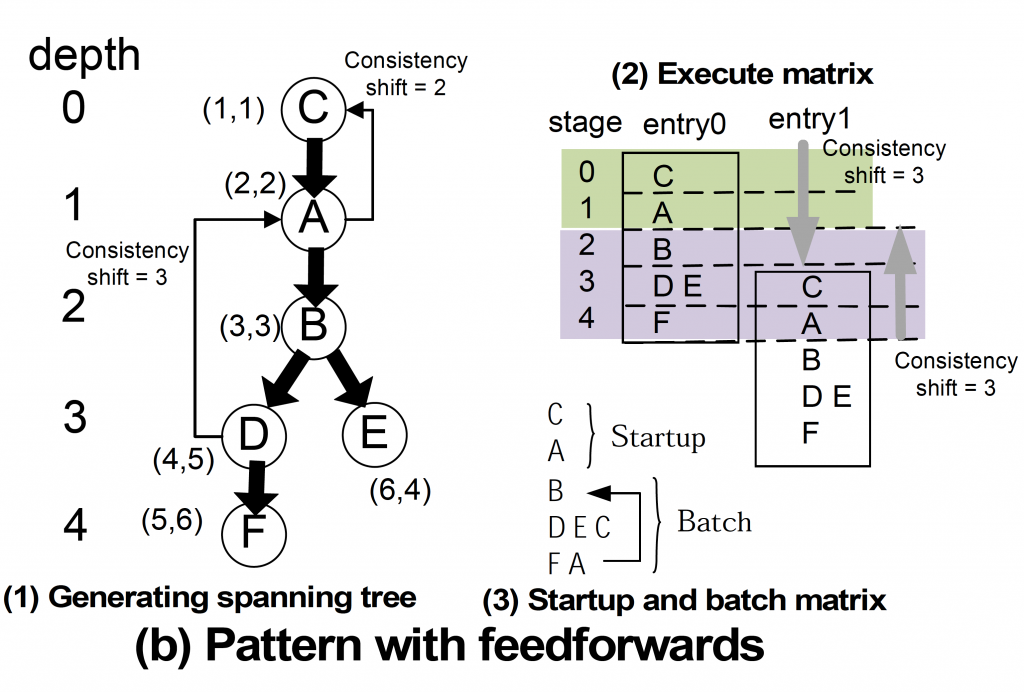
図3:PEA-STで自動的に並列化する例
以上から、本研究の目的にあるマクロ並列化 を自動的に行い、通信までを自動生成するコ ンパイラの開発ができた。この技術によって、これまでのGPU へのプログラミングは格段に 見通しの良いものになると共に、自動的に GPU の潜在能力を引き出すため、細かなチュ ーニングは必要のない新しいプログラミン グ環境を開発できた。
物性物理学への応用
以上の成果を使って、計算物性物理学のシミュレーションに応用した。超伝導物質の温度変化に伴う電子の振る舞いを、 Kernel Polynomial Method と呼ばれる固有値解法を使ったものと、モンテカルロ法による方法を使って、GPU クラスタで並列化し、シミュレーションを行った。その性能は、GPU クラスタにおいて、CPU での並列化に比べ、GPU での並列化が 12 倍にも及ぶことがわかり、十分に計算性能の高密度化ができたことを確認できた。
このように、スーパーコンピュータなどから比べ小規模なGPU クラスタであっても、十分に性能を引き出すことができるようになったため、スーパーコンピュータの性能を底上げするだけでなく、研究室単位でも高い計算性能を得られる基盤技術となることが今後、予想される。
以上のような成果が得られたが、本研究では以下のような将来への課題も残された。
(1) 近年、組込み型のメニーコアプラットフォームが市場で見られるようになった。これらのプラットフォームでも本研究成果が有効であることを示す必要がある。
(2) 上記の PEA-ST によって並列化の組合せを求めると、膨大な組合せが発生する可能性もある。このような場合のために並列化の条件を、プログラム実行先のプラットフォームの仕様に合わせ決定する機構が必要になる。
(3) 本研究での成果を簡易に使えるよう、 GUI といったプログラミングのためのツールを拡充する必要がある。
発表論文
[雑誌論文]
- Guyue Wang, Koichi Wada, Shinichi Yamagiwa, Optimization in the parallelism extraction algorithm with spanning tree on a multi-GPU environment,IEEJ TRANSACTIONS ON ELECTRICAL AND ELECTRONIC ENGINEERING 862 – 869, 2019年
- Shinichi Yamagiwa, Guyue Wang and Koichi Wada, Development of an Algorithm for Extracting Parallelism and Pipeline Structure from Stream-based Processing flow with Spanning Tree, International Journal of Networking and Computing, Vol 5,No1, 2015年, pp.159-179.
- Shinichi Yamagiwa, Heterogeneous Computing, The Journal of the Institute of Image Information and Television Engineers, 2014年
- Shinichi Yamagiwa, Invitation to a Standard Programming Interface for Massively Parallel Computing Environment: OpenCL,International Journal of Networking and Computing Vol 2(No 2) 188-205, 2012年1月
- Shinichi Yamagiwa, Koichi Wada, Performance impact on resource sharing among multiple CPU- and GPU-based applications,International Journal of Parallel, Emergent and Distributed Systems 26(4) 313 – 329, 2010年
- Gabriel Falcao, Shinichi Yamagiwa, Vitor Silva, Leonel Sousa, Parallel LDPC Decoding on GPUs Using a Stream-Based Computing Approach,JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 24(5) 913 – 924, 2009年
- Shinichi Yamagiwa, Leonel Sousa, Modelling and programming stream-based distributed computing based on the meta-pipeline approach,International Journal of Parallel,Emergent and Distributed Systems Vol. 24(Issue 4) 311-330, 2009年
- Shinichi Yamagiwa, Leonel Sousa, Caravela: A Novel Stream-Based Distributed Computing Environment,COMPUTER 40(5) 70, 2007年
[学会発表]
- Guyue Wang, Koichi Wada, Shinichi Yamagiwa, Performance Evaluation of Parallelizing Algorithm Using Spanning Tree for Stream-Based Computing, 2016 FOURTH INTERNATIONAL SYMPOSIUM ON COMPUTING AND NETWORKING (CANDAR) 497 – 503, 2016年
- Guyue Wang, Parallelism Extraction Algorithm from Stream-based Processing Flow applying Spanning Tree, IPDPS/APDCM14, 2014 年 5 月 19日, Phoenix (USA).
- Shinichi Yamagiwa, Exploiting Execution Order and Parallelism from Processing Flow Applying Pipeline-based Programming Method on Manycore Accelerators, 2013-42nd International Conference on Parallel Processing, 2013 年 10 月 1 日, Lyon(France).
- Shinichi Yamagiwa, Scenario-based Execution Method for Massively Parallel Accelerators, 2013-12th IEEE International Conference on Trust, Security and Privacy in Computing and Communications, 2013 年 7 月 16日, Melbourne, (Australia).
- Shinichi Yamagiwa, Ryoyu Watanabe, Koichi Wada, Operation Synchronization Technique on Pipeline-based Hardware Synthesis Applying Stream-based Computing Framework, 15th Workshop on Advances in Parallel and Distributed Computational Models/IPDPS2013, 2013 年 5 月 20 日, Boston (USA).
- Shinichi Yamagiwa, Masahiro Arai, Koichi Wada,Efficient handling of stream buffers in GPU stream-based computing platform,Proceedings of 2011 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing, 2011
- Shinichi Yamagiwa, Masahiro Arai, Koichi Wada, Design and Implementation of a Uniform Platform to Support Multigenerational GPU Architectures for High Performance Stream-Based Computing, 2010 First International Conference on Networking and Computing, 2010
- Shinichi Yamagiwa, Leonel Sousa, CaravelaMPI: Message Passing Interface for Parallel GPU-Based Applications, 2009 Eighth International Symposium on Parallel and Distributed Computing, 2009
- Shinichi Yamagiwa, Koichi Wada, Performance study of interference on GPU and CPU resources with multiple applications, 2009 IEEE International Symposium on Parallel & Distributed Processing, 2009
- Shinichi Yamagiwa, Leonel Sousa, Diogo Antao, Data buffering optimization methods toward a uniform programming interface for gpu-based applications, Proceedings of the 4th international conference on Computing frontiers – CF2007, 2007
- Shinichi Yamagiwa, Leonel Sousa, Design and implementation of a tool for modeling and programming deadlock free meta-pipeline applications, 2008 IEEE International Symposium on Parallel and Distributed Processing, 2008
- Shinichi Yamagiwa, Diogo Ricardo, Cardoso Antao, Leonel Sousa, Design and implementation of a graphical user interface for stream-based distributed computing, the IASTED International Conference on Parallel and Distributed Computing and Networks (PDCN 2008), 2008
- Gabriel Falcao, Shinichi Yamagiwa, Vitor Silva, Leonel Sousa, Stream-Based LDPC Decoding on GPUs, First Workshop on General Purpose Processing on Graphics Processing Units (GPGPU), 2007
- Shinichi Yamagiwa, Leonel Sousa, Tomas Brandao, Meta-Pipeline: A New Execution Mechanism for Distributed Pipeline Processing, Sixth International Symposium on Parallel and Distributed Computing (ISPDC2007), 2007
- Shinichi Yamagiwa, Leonel Sousa, Design and implementation of a stream-based distributedcomputing platform using graphics processing units, Proceedings of the 4th international conference on Computing frontiers – CF2007, 2007
- Leonel Sousa, Shinichi Yamagiwa, Caravela: A Distributed Stream-Based Computing Platform, 3rd HiPEAC Industrial Workshop, IBM Haifa Labs, Israel, 2007
[書籍]
- Shinichi Yamagiwa, Gabriel Falcao, Koichi Wada and Leonel Sousa, Horizons in Computer Science Research. Volime 11,
主な獲得研究予算
- 科学技術振興機構 さきがけ 知の創生と情報社会「高性能ストリーム・コンピューティング環境の構築」研究期間:2010〜2013
- 科研費 基盤研究(B)「ストリーム指向プログラムのマクロ並列化の研究」 研究期間:2012〜2014