Research and development of macro parallelization methods targeted to stream-based programs
Research and development of macro parallelization methods targeted to stream-based programs
Research Category:Grant-in-Aid for Scientific Research (B)
Project Period:2012 – 2014
Principal Investigator:Shinichi Yamagiwa
【 Outline 】
The stream-based program has been applied among scientific and industrial computations due to the widely populated manycore accelerators such as GPU. The performance of single GPU is high due to the massively parallel execution of the program. However, considering parallel computing using multiple accelerators, programmers must consider a method for parallelization of the program and its communication timings of the divided programs. Therefore, it is hard to maintain the performance from the parallelized program. This research project aims to develop a programming foundation that can parallelize the stream-based program into multiple GPUs automatically and achieves a scalable performance from the parallel program for GPU.
1.Background at the start of research
Stream-oriented programs are being used as a new paradigm to replace traditional programming methods that randomly access memory. In particular, the use of GPUs for numerical calculations has become widespread, and they are being used from scientific and technological calculations to industrial products with the support of the expansion of programming environments such as OpenCL and CUDA [Reference (1)]. In particular, regarding science and technology computing, the data parallelism of stream-oriented programs is utilized, and dense parallel execution by a small processor inside the GPU achieves 10 to 100 times the performance of conventional von Neumann CPUs. Recently, a GPU cluster environment in which multiple GPUs are connected via a network has attracted attention.
GPU clusters take into account macro parallelization of stream-oriented programs across multiple GPUs. This is different from the traditional vectorization that divides the memory access range, and aims at parallel execution by dividing the data stream. At this time, communication between GPU chips is required, which is not necessary for micro-parallelization inside the GPU. Programmers use communication libraries to implement the movement of data streams between GPUs. In this program development, “execution of stream-oriented programs” on GPU and “communication between GPUs” are mixed, and it is extremely difficult to optimize the execution timing of each other. If we can develop a new technology that brings out the effectiveness of nearly 100% of the potential performance of the GPU by performing parallelization including communication optimization, it will be possible to develop a program that realizes the effective performance of Peta FLOPS scale even on a small GPU cluster. It will be possible, and it will be possible to increase the density of computing power with respect to volume and power.
2.Purpose of research
Based on the above background, the objectives of this study are as follows.
(1)Development of a compiler that macro parallelizes a stream-oriented program for a single GPU
With the aim of maximizing the potential performance of a single GPU, we will develop a basic technology that can maximize the overall computational performance even when using multiple GPUs, which will be described later.
(2)Program conversion technology that automatically generates communication code that enables the use of multiple GPUs
In order to perform parallel computing on multiple GPUs, we will develop a basic technology for converting sequentially written programs into a form that can be executed in parallel.
(3)Apply the above two basic technologies to applications such as natural science
3.Research method
In order to achieve the purpose of this research, the research was carried out by the following methods.
(1)Technology that brings out the potential performance of a single GPU
① Development of overhead reduction method for data exchange between GPU and CPU
The GPU and CPU are connected by a peripheral bus such as the PCI bus, and the CPU controls the GPU to download parallel computing programs and data and execute them. The overhead of transferring this data to the GPU side again is large compared to the program execution time on the GPU, which is an overhead. In addition to developing measures to reduce this data transfer, we will develop a programming method that can easily use its functions.
② Development of execution method to reduce program exchange overhead on GPU
In addition to the problem associated with the data exchange in (1) above, it is necessary to re-download the program from the CPU side when executing a different program on the GPU, which is an overhead. We will develop a method to reduce this overhead and a programming interface that can easily use its functions.
(2)Development of program conversion method for parallel use of multiple GPUs
If the program is divided into parts or scheduled for parallel execution, develop a mechanism to process them in a pipeline on multiple GPUs.
(3)Application to computational physics
Use the above performance improvement measures and apply them to the simulation of computational condensed matter physics.
4.Research achievement
The following results were obtained from this study.
In this research, we aimed to make a further leap based on the research results obtained in [Cited document (2)]. As a result of this, we have developed a programming environment called Caravela that easily executes parallel computing by mapping the GPU program called flow-model and the data structure that defines its input / output to the GPU, as shown in Fig. 1. .. The application algorithm is constructed by connecting multiple Flow-models, and each flow-model is mapped to a single GPU. Using this research base, we were able to obtain the following results.
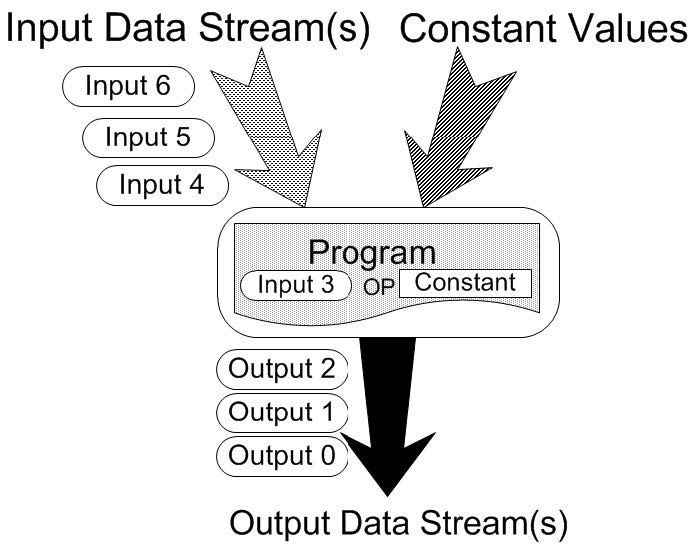
FIGURE1:Caravelaのflow-model
(1)Program execution method without communication with host CPU in GPU single performance
Using a method called the Swap method, in which the input / output buffers to the GPU can be replaced by the GPU only by operating the pointer before and after program execution, dramatically improves the performance of recursive programs that reuse output data. Can be improved [references]. In addition to this optimization related to data movement, in this research, by combining programs from multiple GPUs and combining them with a swap method, if they are executed continuously on the GPU side, the application can be executed without replacing the programs. We have developed a scenario-based execution method [Academic Table ③]. The swap method and the Scenario-based Execution method enable non-communication execution without moving any data or programs from the host CPU.If you use these methods and describe the input / output connections of the flow-model in a script like a conventional shell program, it will be automatically executed including the swap method, and the flow-model will be mapped to the GPU and executed. We have developed a simple program environment CarSh [Presentation ④]. CarSh is a system that can be applied to all systems that have a parallel processor that cooperates with a CPU called an accelerator such as GPU, and can also execute GPU etc. with only a script. CarSh is implemented on the system hierarchy as shown in Fig. 2, and even programmers who do not know the detailed programming method in GPU can prepare a GPU program, define a flow-model, and implicitly use the swap method. However, we were able to provide a new programming interface that enables parallel computing that draws out the potential performance of the GPU.
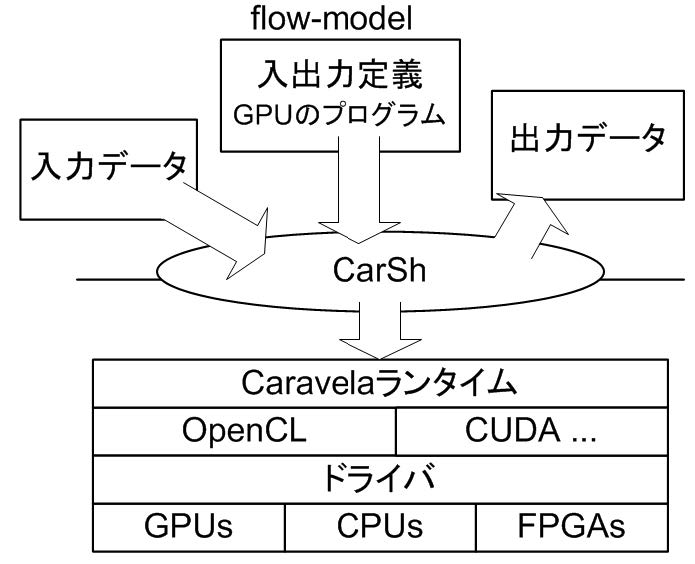
FIGURE2:System configuration of CarSh
(2)A compiler that automatically generates a parallel execution pipeline on multiple GPUs
CarSh can now run applications with multiple flow-models connected, but only one GPU was used sequentially. We have developed an automatic parallelization method PEA-ST that executes it in a pipeline on multiple GPUs [Journal article (1), conference presentation (1) and (2)].
The PEA-ST algorithm automatically extracts parallelism from an application that connects multiple flow-models as shown in Fig. 3 and realizes macro parallelization. Multiple flow-models parallelized to macros are assigned to multiple GPUs in parallel and executed at the same time. FIG. 3 shows the steps of this parallelization. Figure 3 (a) shows how the simply connected flow-models are parallelized. As shown in Fig. 3 (a)-(3), it can be executed in parallel on three GPUs. In addition, it automatically generates communication between these GPUs. FIG. 3 (b) shows the case where there is a dependency between flow-models in which the result is fed back. In this case, it is difficult to visually determine which flow-model can be executed in parallel, but as shown in Fig. 3 (b)-(3), automatic parallelization that can be executed by three GPUs is performed.
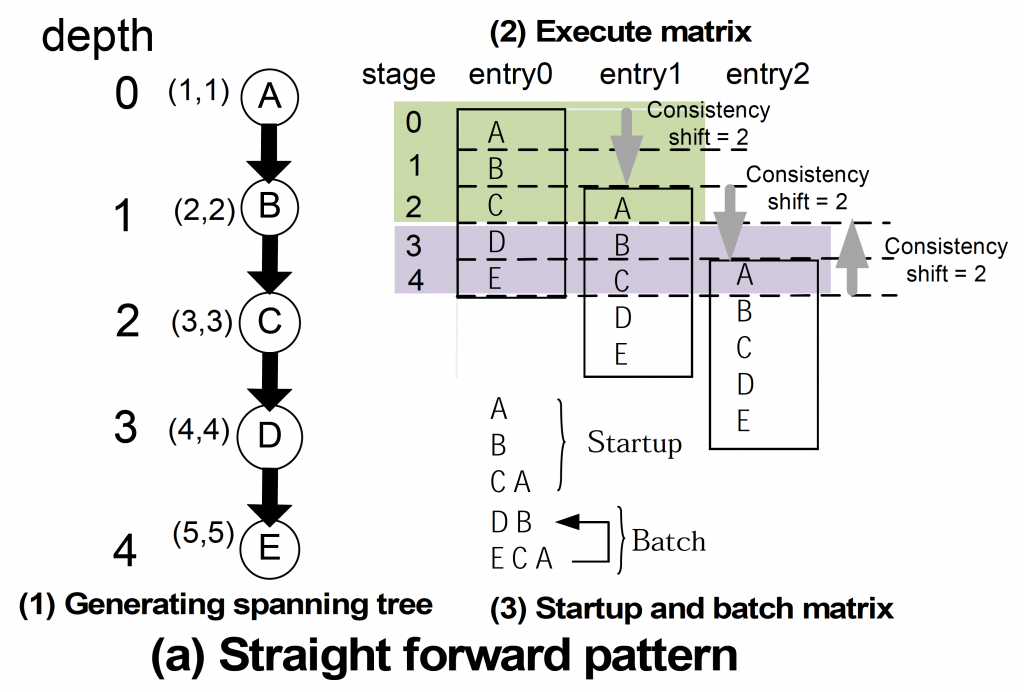
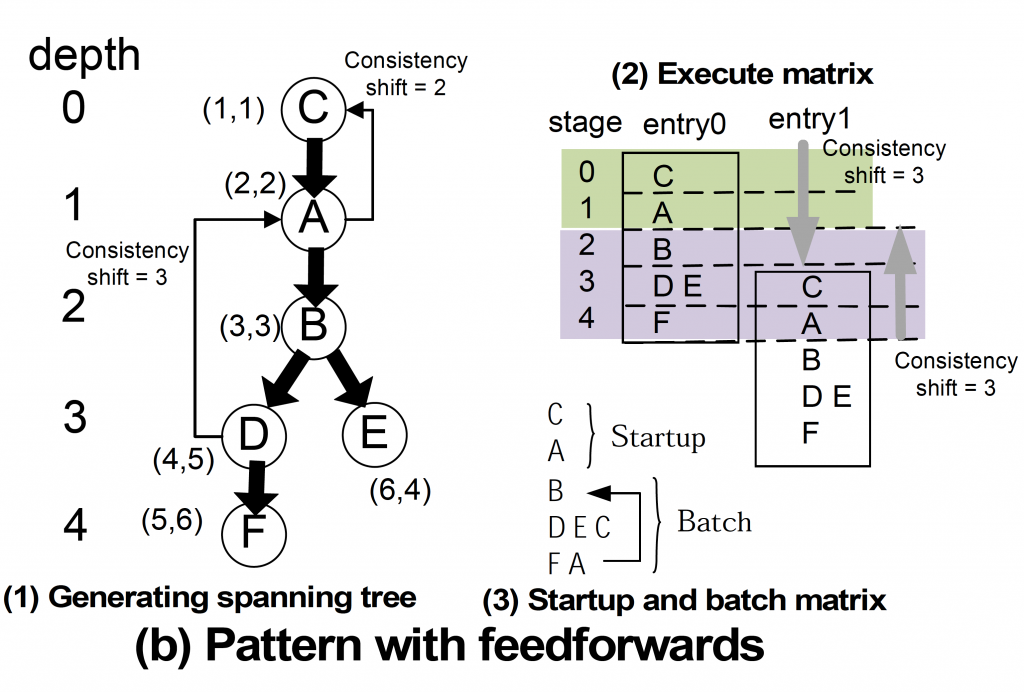
FIGURE3:Example of automatic parallelization with PEA-ST
From the above, we were able to develop a compiler that automatically performs macro parallelization, which is the purpose of this research, and automatically generates communication. This technology has made programming to the GPU much more visible, and has allowed us to develop a new programming environment that does not require detailed tuning because it automatically unlocks the potential of the GPU.
The above results are pioneering research, as no attempt has been made to build a GPU programming environment using the macro parallelization approach both in Japan and overseas.
(3)Application to condensed matter physics
Using the above results, we applied it to the simulation of computational condensed matter physics. The behavior of electrons due to temperature changes in superconducting materials was simulated in a GPU cluster using the eigenvalue solution method called the Kernel Polynomial Method and the Monte Carlo method. As for the performance, it was found that the parallelization on the GPU was 12 times higher than the parallelization on the CPU in the GPU cluster, and it was confirmed that the high density of the calculation performance was sufficiently high. ②③, conference presentation ⑥].
In this way, even a GPU cluster that is smaller than a supercomputer can fully bring out its performance, which not only raises the performance of the supercomputer, but also has high computing performance in each laboratory. It is expected that it will become a basic technology that can be obtained in the future.
Although the above results were obtained, the following issues for the future remained in this study.
(1) In recent years, embedded manycore platforms have become available on the market. It is necessary to show that the results of this research are also effective on these platforms.
(2) Finding parallelization combinations using the above PEA-ST can result in a huge number of combinations. For such a case, a mechanism for determining the parallelization conditions according to the specifications of the platform on which the program is executed is required.
(3) It is necessary to expand programming tools such as GUI so that the results of this research can be used easily.
〈 References 〉
- David B. Kirk and Wen-mei W. Hwu. Programming Massively Parallel Processors: A Hands-On Approach (1st ed.). Morgan Kaufmann Publishers Inc., 2010.
- Shinichi Ya magiwa, leonel Sousa, Caravela: A Novel Stream-Based Distributed Computing Environment, Computer , vol.40, no.5, 2007, pp.70-77.
- Shinichi Ya magiwa, Leonel Sousa, Diogo Antao, Data Buffering optimization methods toward a uniform programming interface for GPU-based applications, Proceeding of ACM Intl’ Conference on Computing Frontiers, 2007, pp. 205 – 212.
5.Related papers
[Journal treatise]
- Guyue Wang, Koichi Wada, Shinichi Yamagiwa, Optimization in the parallelism extraction algorithm with spanning tree on a multi-GPU environment,IEEJ TRANSACTIONS ON ELECTRICAL AND ELECTRONIC ENGINEERING 862 – 869, 2019年
- Shinichi Yamagiwa, Guyue Wang and Koichi Wada, Development of an Algorithm for Extracting Parallelism and Pipeline Structure from Stream-based Processing flow with Spanning Tree, International Journal of Networking and Computing, Vol 5,No1, 2015年, pp.159-179.
- Shinichi Yamagiwa, Heterogeneous Computing, The Journal of the Institute of Image Information and Television Engineers, 2014年
- Shinichi Yamagiwa, Invitation to a Standard Programming Interface for Massively Parallel Computing Environment: OpenCL,International Journal of Networking and Computing Vol 2(No 2) 188-205, 2012年1月
- Shinichi Yamagiwa, Koichi Wada, Performance impact on resource sharing among multiple CPU- and GPU-based applications,International Journal of Parallel, Emergent and Distributed Systems 26(4) 313 – 329, 2010年
- Gabriel Falcao, Shinichi Yamagiwa, Vitor Silva, Leonel Sousa, Parallel LDPC Decoding on GPUs Using a Stream-Based Computing Approach,JOURNAL OF COMPUTER SCIENCE AND TECHNOLOGY 24(5) 913 – 924, 2009年
- Shinichi Yamagiwa, Leonel Sousa, Modelling and programming stream-based distributed computing based on the meta-pipeline approach,International Journal of Parallel,Emergent and Distributed Systems Vol. 24(Issue 4) 311-330, 2009年
- Shinichi Yamagiwa, Leonel Sousa, Caravela: A Novel Stream-Based Distributed Computing Environment,COMPUTER 40(5) 70, 2007年
[Conference presentation]
- Guyue Wang, Koichi Wada, Shinichi Yamagiwa, Performance Evaluation of Parallelizing Algorithm Using Spanning Tree for Stream-Based Computing, 2016 FOURTH INTERNATIONAL SYMPOSIUM ON COMPUTING AND NETWORKING (CANDAR) 497 – 503, 2016年
- Guyue Wang, Parallelism Extraction Algorithm from Stream-based Processing Flow applying Spanning Tree, IPDPS/APDCM14, 2014 年 5 月 19日, Phoenix (USA).
- Shinichi Yamagiwa, Exploiting Execution Order and Parallelism from Processing Flow Applying Pipeline-based Programming Method on Manycore Accelerators, 2013-42nd International Conference on Parallel Processing, 2013 年 10 月 1 日, Lyon(France).
- Shinichi Yamagiwa, Scenario-based Execution Method for Massively Parallel Accelerators, 2013-12th IEEE International Conference on Trust, Security and Privacy in Computing and Communications, 2013 年 7 月 16日, Melbourne, (Australia).
- Shinichi Yamagiwa, Ryoyu Watanabe, Koichi Wada, Operation Synchronization Technique on Pipeline-based Hardware Synthesis Applying Stream-based Computing Framework, 15th Workshop on Advances in Parallel and Distributed Computational Models/IPDPS2013, 2013 年 5 月 20 日, Boston (USA).
- Shinichi Yamagiwa, Masahiro Arai, Koichi Wada,Efficient handling of stream buffers in GPU stream-based computing platform,Proceedings of 2011 IEEE Pacific Rim Conference on Communications, Computers and Signal Processing, 2011
- Shinichi Yamagiwa, Masahiro Arai, Koichi Wada, Design and Implementation of a Uniform Platform to Support Multigenerational GPU Architectures for High Performance Stream-Based Computing, 2010 First International Conference on Networking and Computing, 2010
- Shinichi Yamagiwa, Leonel Sousa, CaravelaMPI: Message Passing Interface for Parallel GPU-Based Applications, 2009 Eighth International Symposium on Parallel and Distributed Computing, 2009
- Shinichi Yamagiwa, Koichi Wada, Performance study of interference on GPU and CPU resources with multiple applications, 2009 IEEE International Symposium on Parallel & Distributed Processing, 2009
- Shinichi Yamagiwa, Leonel Sousa, Diogo Antao, Data buffering optimization methods toward a uniform programming interface for gpu-based applications, Proceedings of the 4th international conference on Computing frontiers – CF2007, 2007
- Shinichi Yamagiwa, Leonel Sousa, Design and implementation of a tool for modeling and programming deadlock free meta-pipeline applications, 2008 IEEE International Symposium on Parallel and Distributed Processing, 2008
- Shinichi Yamagiwa, Diogo Ricardo, Cardoso Antao, Leonel Sousa, Design and implementation of a graphical user interface for stream-based distributed computing, the IASTED International Conference on Parallel and Distributed Computing and Networks (PDCN 2008), 2008
- Gabriel Falcao, Shinichi Yamagiwa, Vitor Silva, Leonel Sousa, Stream-Based LDPC Decoding on GPUs, First Workshop on General Purpose Processing on Graphics Processing Units (GPGPU), 2007
- Shinichi Yamagiwa, Leonel Sousa, Tomas Brandao, Meta-Pipeline: A New Execution Mechanism for Distributed Pipeline Processing, Sixth International Symposium on Parallel and Distributed Computing (ISPDC2007), 2007
- Shinichi Yamagiwa, Leonel Sousa, Design and implementation of a stream-based distributedcomputing platform using graphics processing units, Proceedings of the 4th international conference on Computing frontiers – CF2007, 2007
- Leonel Sousa, Shinichi Yamagiwa, Caravela: A Distributed Stream-Based Computing Platform, 3rd HiPEAC Industrial Workshop, IBM Haifa Labs, Israel, 2007
[Books]
- Shinichi Yamagiwa, Gabriel Falcao, Koichi Wada and Leonel Sousa, Horizons in Computer Science Research. Volime 11,